
Machine Learning: o que é, para que serve e como funciona 2025
Machine learning é uma subárea da inteligência artificial que permite que sistemas aprendam com dados e tomem decisões a partir de dados sem precisar de instruções detalhadas.
A Análise Exploratória de Dados é muito mais do que uma simples fase inicial: é uma etapa estratégica que oferece uma base sólida para qualquer projeto de inteligência de dados. A execução de uma EDA permite identificar padrões iniciais, relacionamentos entre variáveis e inconsistências nos dados que poderiam comprometer as etapas seguintes de uma análise, como a construção de modelos preditivos.
Essa fase é, portanto, a base para uma abordagem sólida em Business Intelligence (BI) e para a construção de modelos de machine learning precisos, permitindo uma compreensão inicial da estrutura dos dados e o embasamento das decisões estratégicas.
Sendo assim, negligenciar a EDA em um projeto de análise pode levar a interpretações equivocadas, comprometendo a assertividade dos insights e, consequentemente, o impacto nos resultados do negócio.
Sua importância reside na capacidade de investigar a fundo o conjunto de dados, antes que qualquer análise preditiva ou prescritiva seja realizada. Ao longo de tal processo, é possível identificar dados inconsistentes, valores fora do padrão (outliers) e até mesmo dados ausentes, que precisam ser tratados para evitar distorções nos resultados.
Em um contexto de vendas, por exemplo, entender o comportamento de compra dos clientes envolve examinar variações sazonais e a influência da localização na demanda dos produtos. Com a EDA, uma empresa pode identificar porque determinados produtos têm picos de venda em épocas específicas ou em determinadas lojas. Ajustando, assim, seu planejamento de estoque e estratégias.
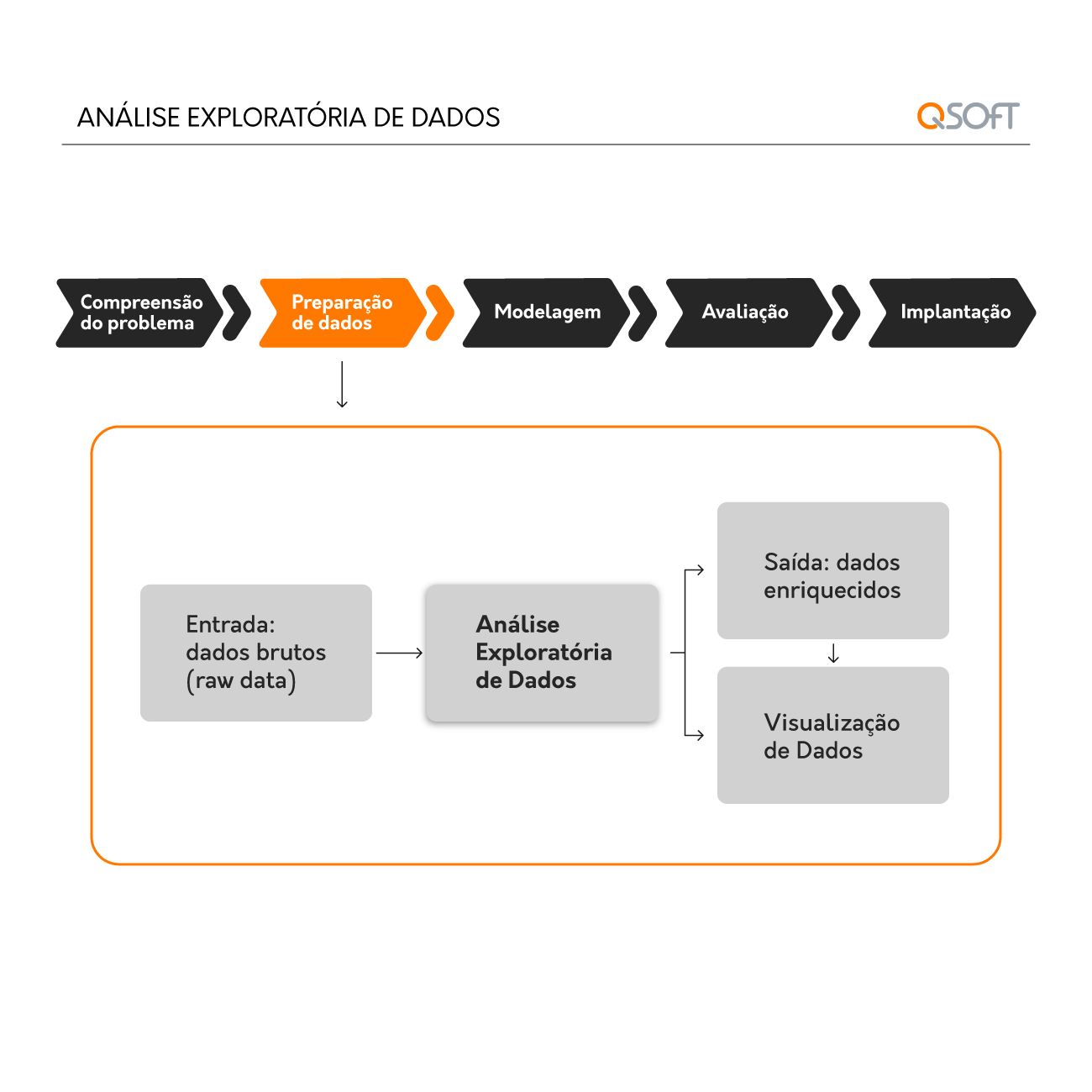
Diversas ferramentas e técnicas facilitam o desenvolvimento, permitindo que analistas de dados realizem uma análise eficiente e visual dos dados. Entre as ferramentas mais utilizadas estão Python e suas bibliotecas específicas para análise de dados, como Pandas, Matplotlib e Seaborn, que ajudam a estruturar e visualizar os dados, facilitando a identificação de padrões e anomalias.
Além de Python, softwares de BI como Tableau e Power BI são amplamente utilizados para análises visuais de dados. Eles oferecem interfaces intuitivas para criar gráficos interativos, que simplificam a visualização dos insights e tornam a análise acessível a diferentes stakeholders. A combinação dessas ferramentas permite uma EDA avançada, que inclui técnicas de análise descritiva e visualizações gráficas.
Na análise descritiva, por exemplo, calcular medidas de tendência central como média, mediana e moda ajuda a entender a distribuição básica dos dados. A variabilidade, medida pelo desvio padrão e variância, indica se os dados estão concentrados ou dispersos.
A Análise Descritiva é uma das primeiras etapas cruciais da Análise Exploratória de Dados (EDA), funcionando como uma fundação sólida para qualquer projeto de Business Intelligence (BI). A EDA, com seu foco na análise descritiva, possibilita um entendimento inicial que guia as etapas subsequentes de modelagem e análise preditiva.
A análise descritiva não se limita apenas ao cálculo de estatísticas básicas, ela envolve uma exploração mais profunda das características dos dados, sendo essencial para identificar a estrutura dos dados, as relações entre as variáveis e qualquer problema potencial, como dados ausentes ou inconsistências.
Quando realizada de forma eficaz, a análise descritiva ajuda a garantir que as etapas seguintes da análise sejam baseadas em uma compreensão sólida dos dados.
Enquanto as medidas de tendência central ajudam a identificar o centro dos dados, as medidas de variabilidade oferecem insights sobre como esses dados estão dispersos. As principais medidas nesse caso incluem:
E ainda existem:
Essas métricas são essenciais para entender a consistência dos dados e identificar possíveis anomalias que poderiam impactar as análises futuras.
Padrões podem indicar tendências ao longo do tempo, ciclos sazonais ou comportamentos repetitivos que podem ser explorados para otimização de estratégias de negócios. Ferramentas de visualização, como gráficos de linha e heatmaps, são frequentemente utilizadas para facilitar essa análise.
Os gráficos de linha são úteis para mostrar como as variáveis mudam ao longo do tempo. Por exemplo, ao analisar as vendas mensais de um produto, um gráfico de linha pode revelar tendências sazonais e contribuir para o planejamento de campanhas específicas.
Os heatmaps, ou mapas de calor, são outra técnica eficaz que permite visualizar dados em forma de matriz, onde a intensidade de cor indica a magnitude dos valores. Por exemplo, um heatmap de vendas por região e mês pode destacar quais áreas estão apresentando desempenho superior ou inferior, permitindo uma análise direcionada para entender os motivos por trás dessas variações.
A preparação de dados é uma das etapas mais críticas em qualquer projeto de análise de dados, frequentemente classificada como uma das fases que consome mais tempo. Um modelo de machine learning ou análise preditiva é tão bom quanto os dados que alimentam. Portanto, assegurar a qualidade, a integridade e a adequação dos dados é fundamental para garantir resultados confiáveis e acionáveis.
Durante esta fase, três áreas principais são de grande importância: limpeza de dados, transformação e engenharia de recursos. Cada uma dessas etapas desempenha um papel singular na qualidade do modelo final.
A limpeza de dados compreende a identificação de falhas, isso pode incluir a remoção de duplicatas, o tratamento de valores ausentes, a correção de erros de digitação e a padronização de formatos. Uma vez que, dados imprecisos ou inconsistentes podem levar a análises enganosas.
Subsequente a limpeza, ocorre a transformação de dados, responsável pelo ajuste dos dados para que estejam prontos para análise. Esse processo pode ser particularmente importante para algoritmos de machine learning que são sensíveis à escala dos dados, como regressão logística e máquinas de vetor de suporte (SVM).
Outra transformação comum é a codificação de variáveis categóricas. Variáveis que são não numéricas precisam ser convertidas em um formato que os algoritmos de modelagem possam entender.
A engenharia de recursos é uma das etapas mais criativas e impactantes da preparação para modelagem, voltada a criação de novas variáveis (ou recursos) a partir dos dados existentes.
A escolha dos recursos certos pode aumentar significativamente a capacidade do modelo de capturar padrões e fazer previsões precisas. Essa etapa exige tanto conhecimento técnico quanto compreensão do domínio, pois a criação de variáveis deve estar alinhada aos objetivos de negócios e às perguntas que se deseja responder.
Ao longo desta jornada pela Análise Exploratória de Dados, fica claro que o sucesso nas decisões estratégicas depende de uma compreensão profunda e precisa dos dados. Na QSOFT, sabemos que cada dado conta uma história e estamos aqui para desvendar o que vai impulsionar sua empresa para novos patamares.
Temos a expertise e as ferramentas necessárias para guiá-lo em cada etapa desse processo. Desde a coleta de dados até a modelagem preditiva, nossa abordagem personalizada garantirá que você não apenas entenda os seus dados, mas também potencialize decisões de negócios com informações que fazem a diferença.
Fale com a gente e descubra como podemos transformar seus dados em estratégias vencedoras.
Compartilhe o post
Machine learning é uma subárea da inteligência artificial que permite que sistemas aprendam com dados e tomem decisões a partir de dados sem precisar de instruções detalhadas.

As tendências de inteligência artificial em 2025 estão moldando o futuro dos negócios. Com avanços como IA multimodal, democratização das plataformas, agentes autônomos e personalização em tempo real, a tecnologia deixa de ser promessa e se torna prática estratégica.

A análise de dados beneficia o setor de saúde. As seguradoras de saúde conseguem usar a análise de dados para detectar e prever NIPs, melhorar a qualidade dos atendimentos, identificar e prever fraudes, além de gerenciar e alocar melhor seus recursos.
© QSOFT, 2024
Sobre Nós
Propósito
Carreira
Serviço
Business Intelligence
Cloud Computing
Data & Analytics
Governança de Dados
Inteligência Artificial
IT Service Management
Sistemas de Informação
Transformação Digital
Web Analytics
Treinamentos
Cases
Insights